Production AI 🚀🤖🏗️
Learn the difference between a demo that works on your laptop and a production AI system that serves real users while you sleep — covering the three pillars every production system needs: reliability, observability, and scalability.
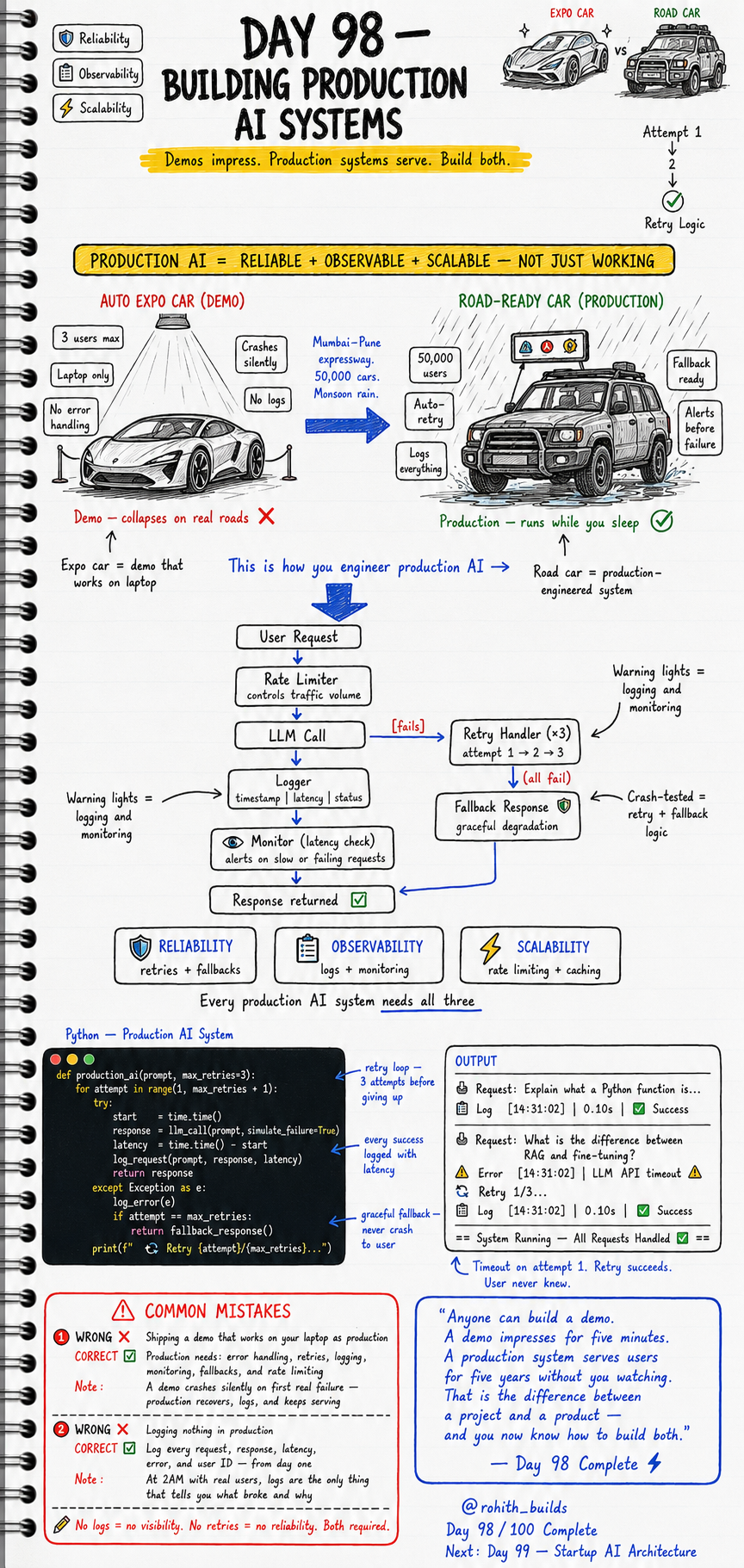
Day 98: Building Production AI Systems
Why Should I Care?
Anyone can build a demo. A demo impresses for five minutes. A production system serves users for five years without you watching. That is the difference between a project and a product. If RohithBuilds goes down at 2AM when a student is studying, there is no you to fix it manually. The system must handle it — retry, fallback, log, recover — all on its own. Today you learn how to build AI systems that run while you sleep.
Core Concept
Production AI is not just working code. It is reliable plus observable plus scalable — all three together. Reliability means the system retries when things fail and falls back gracefully when all retries are exhausted. Observability means every request, response, latency, and error is logged — so you know exactly what broke and why. Scalability means the system controls traffic volume with rate limiting so it does not collapse under real load. A demo has none of these. A production system has all three. Every production AI system needs all three.
How It Works
Think of two cars. The expo car is your demo — beautiful, impressive, works perfectly on a smooth showroom floor. Put it on the Mumbai-Pune expressway in monsoon rain with 50,000 cars and it collapses. No error handling. No logs. Crashes silently. The road car is your production system — built for real conditions. Auto-retry when the engine hiccups. Logs everything. Fallback ready. Alerts before failure. Road car runs while you sleep. Expo car needs you standing next to it at all times. Every user request in a production AI system flows through five stages: rate limiter, LLM call, logger, monitor, response returned. If the LLM call fails, a retry handler tries up to three times. If all three fail, a fallback response returns gracefully — user never sees a crash.
User Request
|
Rate Limiter -- controls traffic volume
|
LLM Call -- [fails] --> Retry Handler (x3)
| attempt 1 -> 2 -> 3
Logger -- timestamp | latency | status
| (all fail)
Monitor -- alerts on slow or failing requests --> Fallback Response
|
Response Returned
RELIABILITY = retries + fallbacks
OBSERVABILITY = logs + monitoring
SCALABILITY = rate limiting + caching
Real World Connection
When you send a message on WhatsApp and it says "delivery failed — tap to retry" — that is a reliability layer at work. When Swiggy shows "something went wrong, try again" instead of a blank crash screen — that is a fallback response. When PhonePe logs every transaction with timestamp, amount, and status so they can audit failures at 2AM — that is observability. When Zomato slows down your API requests during a surge instead of crashing — that is rate limiting for scalability. Every app you use daily has all three pillars running silently. Now you know how to build them yourself.
Examples
import time
def production_ai(prompt, max_retries=3):
for attempt in range(1, max_retries + 1):
try:
start = time.time()
response = llm_call(prompt, simulate_failure=True)
latency = time.time() - start
log_request(prompt, response, latency)
return response
except Exception as e:
log_error(e)
if attempt == max_retries:
return fallback_response()
print(f" Retry {attempt}/{max_retries}...")
# OUTPUT:
# Request: Explain what a Python function is...
# Log [14:31:02] | 0.10s | Success
#
# Request: What is the difference between RAG and fine-tuning?
# Error [14:31:02] | LLM API timeout
# Retry 1/3...
# Log [14:31:02] | 0.10s | Success
#
# == System Running -- All Requests Handled ==
# Timeout on attempt 1. Retry succeeds. User never knew.
Common Mistakes
Mistake 1 — Shipping a demo as production:
-- WRONG:
def ai_response(prompt):
return llm_call(prompt)
# no retries, no logging, no fallback
# crashes silently on first real failure
# user sees a blank screen and never comes back
-- CORRECT:
def ai_response(prompt, max_retries=3):
for attempt in range(1, max_retries + 1):
try:
return llm_call(prompt)
except Exception as e:
log_error(e)
if attempt == max_retries:
return fallback_response()
# production recovers, logs, and keeps serving
Mistake 2 — Logging nothing in production:
-- WRONG:
response = llm_call(prompt)
return response
# no log of what was requested or what failed
-- CORRECT:
start = time.time()
response = llm_call(prompt)
latency = time.time() - start
log_request(prompt, response, latency)
# log every request, response, latency, error, and user ID
# from day one -- not after something breaks
# at 2AM with real users, logs are the only thing
# that tells you what broke and why
# no logs = no visibility. no retries = no reliability. both required.
Mini Challenge
Mini Challenge
Take any AI function you have already built — your chatbot, your summariser, anything. Wrap it in a retry loop with max_retries=3. Add a try/except block that logs the error and returns a fallback string on final failure. Add a latency log that prints timestamp, response time, and status after every call. Run it and force a failure by passing a bad prompt or disconnecting your API key. Watch the retry loop fire. Watch the fallback return. Watch the log capture everything. You just made your first production-grade AI function. That is the whole lesson in your hands.
Quick Quiz
Q: What are the three pillars every production AI system must have?
A: Reliability — retries and fallbacks. Observability — logs and monitoring. Scalability — rate limiting and caching. Every production AI system needs all three.
Q: What should a production system return when all three retries are exhausted?
A: A fallback response — a graceful, pre-written message that tells the user something went wrong without crashing the app or showing a blank screen.
Q: Why should you log from day one instead of waiting until something breaks?
A: Because at 2AM with real users, logs are the only thing that tells you what broke and why. Without logs you are blind — you cannot fix what you cannot see.
Bonus Knowledge
The five-stage production flow — rate limiter, LLM call, logger, monitor, response — maps directly to how enterprise AI systems are built at companies like Google, Amazon, and Anthropic. Rate limiting protects your LLM API budget. A single bug in a loop without rate limiting can burn your entire monthly quota in seconds. Monitoring adds warning lights — it alerts you when latency spikes above a threshold before users start complaining. Caching is the next level of scalability — store responses for repeated prompts so the LLM is not called unnecessarily, cutting cost and latency at the same time. Demos impress. Production systems serve. Build both — but always know which one you are shipping.
Key Takeaways
Key Takeaways
- Production AI is reliable plus observable plus scalable — not just working code on a laptop.
- Reliability means retry logic up to three attempts and a graceful fallback when all retries fail.
- Observability means logging every request, response, latency, and error from day one — not after something breaks.
- Scalability means rate limiting controls traffic volume so the system survives real load without collapsing.
- A demo crashes silently on first real failure. A production system recovers, logs, and keeps serving.
- At 2AM with real users, logs are the only thing that tells you what broke and why. No logs equals no visibility.
- Anyone can build a demo. A production system serves users for five years without you watching. Now you know how to build both.
Continue Learning with Rohi
You've used your 3 free Rohi questions. Create a free account to continue learning.