Transformers ⚖️⚡🧠
Discover how Transformers revolutionised AI by processing all words simultaneously using attention — unlike RNNs that forget early context — and use HuggingFace to run a full pretrained Transformer in just one line of code.
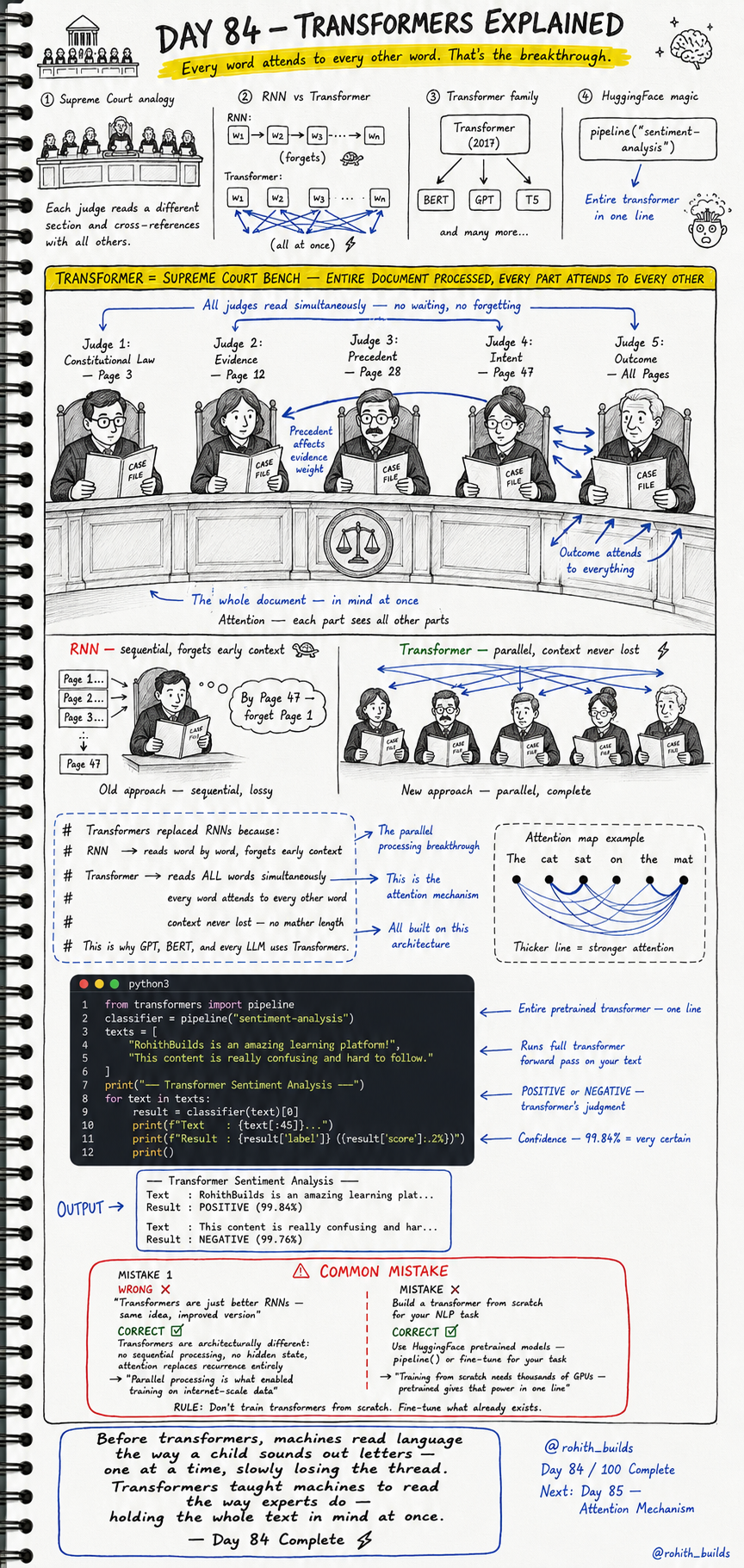
Day 84: Transformers Explained — Every Word Attends to Every Other Word
Why Should I Care?
Every AI tool you use that involves language — ChatGPT, Google Translate, GitHub Copilot, Gemini — is built on one architecture invented in 2017: the Transformer. Before Transformers, machines read language like a child sounding out letters one at a time, slowly losing the thread. Transformers taught machines to read the way experts do — holding the whole text in mind at once. Understanding this means you understand the engine inside every LLM on the planet.
Core Concept
A Transformer is like a Supreme Court bench. Imagine five judges each reading a different section of the same case file — Constitutional Law, Evidence, Precedent, Intent, Outcome — all simultaneously. Every judge can cross-reference every other judge''s section at any time. No waiting. No forgetting. The entire document is in mind at once. That is exactly how a Transformer processes language. Every word attends to every other word at the same time. That parallel attention is the breakthrough.
How It Works
Before Transformers, the best tool was an RNN — Recurrent Neural Network. An RNN reads text word by word, left to right, like a person reading page by page. By the time it reaches page 47 it has already forgotten page 1. A Transformer reads all words simultaneously and uses an attention mechanism to let every word check its relationship with every other word. Context is never lost no matter how long the text is. This is why GPT, BERT, T5, and every modern LLM is built on Transformers — not RNNs.
RNN vs Transformer:
RNN:
w1 --> w2 --> w3 --> ... --> wn
Reads word by word, sequentially
Forgets early context by the end
Old approach — sequential, lossy
Transformer:
w1, w2, w3, ... wn (all at once)
Every word attends to every other word
Context never lost — no matter the length
New approach — parallel, complete
Attention map example ("The cat sat on the mat"):
"cat" strongly attends to "mat" and "sat"
"sat" strongly attends to "cat" and "on"
Thicker line = stronger attention between words
The Transformer family (all built on this architecture):
BERT --> Understanding text, search, classification
GPT --> Generating text, completing sentences
T5 --> Translation, summarisation, Q and A
Real World Connection
When you search something on Google, BERT reads your entire query at once — every word attending to every other word — and finds the most relevant result. When ChatGPT writes a reply to your message, GPT processes your full conversation context simultaneously before generating the next word. When you use Google Translate to convert Hindi to English, a Transformer encoder reads the Hindi sentence all at once and a decoder writes the English. Every language feature in every app you use daily is a Transformer running underneath.
Examples
from transformers import pipeline
# Load an entire pretrained Transformer in one line
classifier = pipeline("sentiment-analysis")
texts = [
"RohithBuilds is an amazing learning platform!",
"This content is really confusing and hard to follow."
]
print("— Transformer Sentiment Analysis —")
for text in texts:
result = classifier(text)[0]
print(f"Text : {text[:45]}...")
print(f"Result : {result[''label'']} ({result[''score'']:.2%})")
print()
# OUTPUT:
# — Transformer Sentiment Analysis —
# Text : RohithBuilds is an amazing learning plat...
# Result : POSITIVE (99.84%)
#
# Text : This content is really confusing and har...
# Result : NEGATIVE (99.76%)
#
# One line loads a full Transformer trained on millions of sentences.
# pipeline() runs the complete forward pass on your text.
# Confidence 99.84% = the model is very certain.
Common Mistakes
Two mistakes that beginners make when first learning about Transformers. First, thinking they are just a better version of RNNs. Second, trying to build one from scratch for their own project.
-- MISTAKE 1: Thinking Transformers are just improved RNNs --
WRONG:
"Transformers are just better RNNs —
same idea, improved version"
CORRECT:
Transformers are architecturally different.
No sequential processing. No hidden state.
Attention replaces recurrence entirely.
NOTE: "Parallel processing is what enabled
training on internet-scale data."
RULE: Transformer is not an upgrade to RNN — it is a replacement.
-- MISTAKE 2: Building a Transformer from scratch --
WRONG:
Build a Transformer from scratch for your NLP task.
Result: needs thousands of GPUs and months of training.
CORRECT:
Use HuggingFace pretrained models.
pipeline() or fine-tune for your specific task.
NOTE: "Training from scratch needs thousands of GPUs —
pretrained gives that power in one line."
RULE: Don''t train Transformers from scratch.
Fine-tune what already exists.
Mini Challenge
Mini Challenge
Install the transformers library using pip install transformers and run the sentiment analysis code from the Examples section. Then add three more sentences of your own — one clearly positive like a great Zomato review, one clearly negative like a bad experience, and one tricky neutral sentence. Print the label and confidence score for each. Check if the Transformer gets the tricky one right. You just ran a model trained on billions of sentences with four lines of code.
Quick Quiz
Q1: What is the key difference between how an RNN and a Transformer process text? A1: An RNN reads word by word sequentially and forgets early context. A Transformer reads all words simultaneously and every word attends to every other word — context is never lost. Q2: Name three models that are part of the Transformer family. A2: BERT, GPT, and T5 — all built on the same Transformer architecture introduced in 2017. Q3: Why should you use HuggingFace pipeline() instead of building a Transformer from scratch? A3: Training from scratch requires thousands of GPUs and months of compute. Pretrained models give you that power in a single line of code — always fine-tune what already exists.
Bonus Knowledge
The original Transformer paper published in 2017 was titled "Attention Is All You Need" — and that title turned out to be exactly right. The attention mechanism is so powerful that it completely replaced RNNs, LSTMs, and GRUs in almost every language task within just two years. The HuggingFace library that you used in the code example hosts over 500,000 pretrained models built on this architecture — covering every language, every task, and every domain imaginable. BERT powers Google Search. GPT powers ChatGPT. Both came from that one 2017 paper. That is how fast a single good idea can change everything in AI.
Key Takeaways
Key Takeaways
- Transformers process all words simultaneously using attention — every word attends to every other word at once.
- RNNs read sequentially and forget early context — Transformers replaced them because attention never loses context.
- The Transformer family includes BERT for understanding, GPT for generating, and T5 for translation and summarisation.
- HuggingFace pipeline() loads an entire pretrained Transformer in one line — no training required.
- Never build a Transformer from scratch for a real project — always fine-tune a pretrained model instead.
- Every major language AI tool — ChatGPT, Google Translate, GitHub Copilot — runs on the Transformer architecture.
Continue Learning with Rohi
You've used your 3 free Rohi questions. Create a free account to continue learning.