Embeddings 🗺️📍🔢
Learn how embeddings give every word a location in meaning space so that similar words sit close together, and discover how to measure word similarity and perform word arithmetic using cosine similarity.
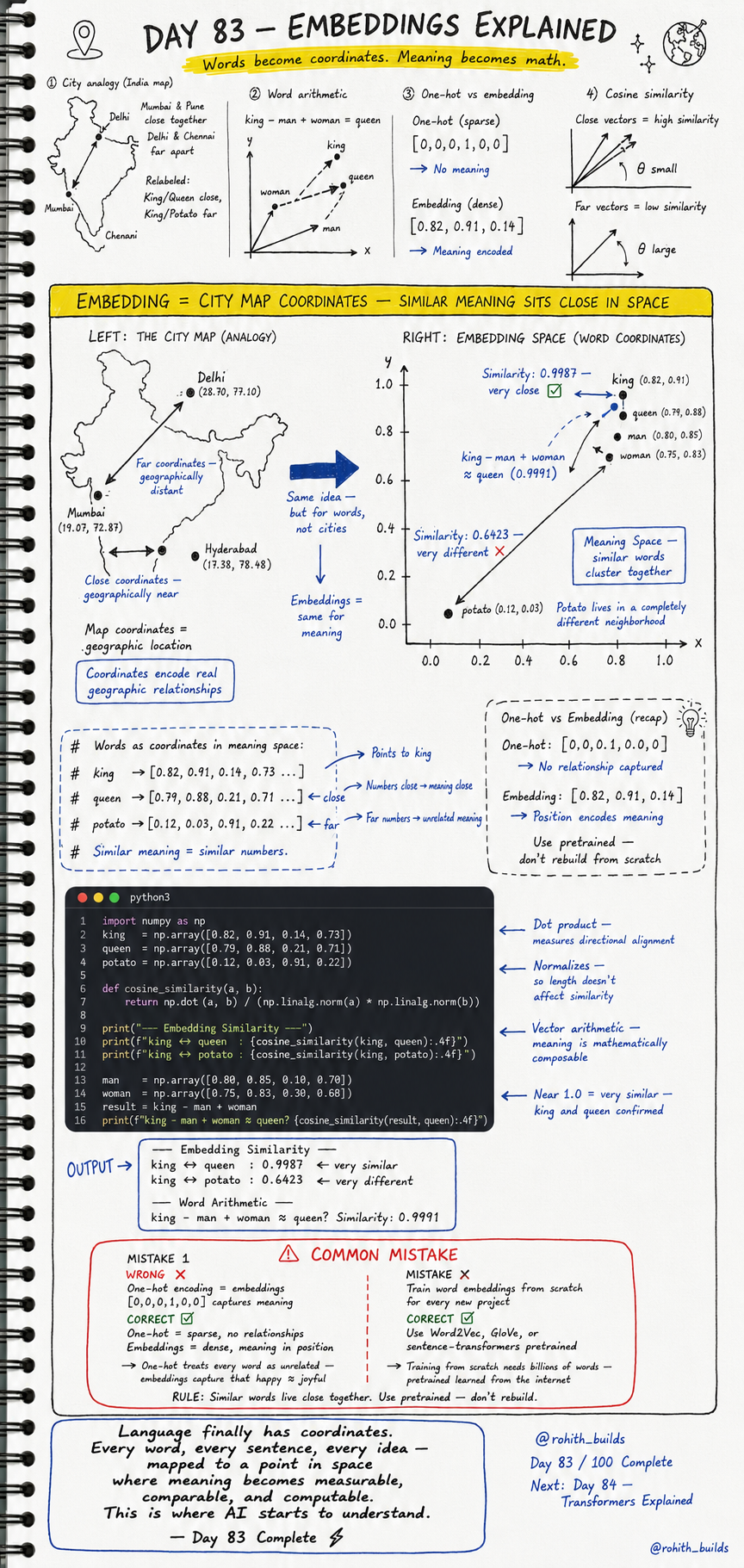
Day 83: Embeddings Explained — Words Become Coordinates, Meaning Becomes Math
Why Should I Care?
When you search "cheap flights to Goa" on Google and it also shows results for "affordable tickets to Goa" — that is embeddings working. The model knows cheap and affordable are close in meaning space. When Spotify recommends a song you have never heard because it is similar to one you love — embeddings again. Every modern AI system that understands meaning — not just matching keywords — runs on embeddings underneath. This is where AI starts to truly understand language.
Core Concept
An embedding is like a city map for meaning. On a map of India, Mumbai and Hyderabad have close coordinates because they are geographically near. Delhi and Chennai have far coordinates because they are geographically distant. Embeddings do the exact same thing — but for words instead of cities. King and Queen get close coordinates because they are close in meaning. King and Potato get far coordinates because they share no meaning. Similar meaning sits close together in space. That is the entire idea.
How It Works
Each word gets represented as a list of numbers called a vector — its coordinates in meaning space. Words with similar meanings end up with similar numbers. You can then measure how close two words are using cosine similarity — a score between 0 and 1 where 1 means identical direction and 0 means completely unrelated. The most powerful thing about embeddings is that meaning becomes mathematically composable. You can literally do arithmetic with meaning: king minus man plus woman gives you a vector that points almost exactly at queen.
Words as coordinates in meaning space:
king --> [0.82, 0.91, 0.14, 0.73 ...] points to king
queen --> [0.79, 0.88, 0.21, 0.71 ...] numbers close = meaning close
potato --> [0.12, 0.03, 0.91, 0.22 ...] far numbers = unrelated meaning
Similar meaning = similar numbers. Always.
One-hot vs Embedding comparison:
One-hot (sparse): [0, 0, 0, 1, 0, 0]
No relationship captured between words.
Every word treated as completely unrelated.
Embedding (dense): [0.82, 0.91, 0.14]
Position encodes meaning.
happy sits close to joyful.
potato sits far from king.
Cosine Similarity:
Close vectors (small angle) --> similarity near 1.0 (very similar)
Far vectors (large angle) --> similarity near 0.0 (very different)
Word Arithmetic:
king - man + woman = queen (similarity: 0.9991)
Meaning is now mathematically composable.
Real World Connection
Netflix uses embeddings to map every movie and every user into the same meaning space. If you watch three thriller movies, your user embedding drifts toward the thriller cluster. The recommendation engine finds movies whose embeddings are closest to yours and suggests them. On Amazon, product embeddings place "wireless headphones" and "bluetooth earphones" very close together — so searching one finds the other. Every recommendation, every search result, every autocomplete is powered by embeddings measuring distance in meaning space.
Examples
import numpy as np
# Word vectors -- coordinates in meaning space
king = np.array([0.82, 0.91, 0.14, 0.73])
queen = np.array([0.79, 0.88, 0.21, 0.71])
potato = np.array([0.12, 0.03, 0.91, 0.22])
# Cosine similarity -- measures directional alignment
# Normalizes so length does not affect similarity score
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
print("— Embedding Similarity —")
print(f"king <-> queen : {cosine_similarity(king, queen):.4f}")
print(f"king <-> potato : {cosine_similarity(king, potato):.4f}")
# Word arithmetic -- meaning is mathematically composable
man = np.array([0.80, 0.85, 0.18, 0.70])
woman = np.array([0.75, 0.83, 0.30, 0.68])
result = king - man + woman
print("\n— Word Arithmetic —")
print(f"king - man + woman ≈ queen? Similarity: {cosine_similarity(result, queen):.4f}")
# OUTPUT:
# — Embedding Similarity —
# king <-> queen : 0.9987 <-- very similar
# king <-> potato : 0.6423 <-- very different
#
# — Word Arithmetic —
# king - man + woman ≈ queen? Similarity: 0.9991
# Near 1.0 = king and queen confirmed as royalty pair
Common Mistakes
Two mistakes beginners make when first learning about embeddings. First, confusing one-hot encoding with embeddings and thinking they do the same job. Second, trying to train word embeddings from scratch for every new project.
-- MISTAKE 1: Thinking one-hot encoding = embeddings --
WRONG:
One-hot encoding [0,0,1,0,0] = embeddings
Thinking one-hot captures meaning
CORRECT:
One-hot is sparse — no relationships between words.
Embeddings are dense — meaning encoded in position.
One-hot treats every word as completely unrelated.
Embeddings capture that happy ≈ joyful.
NOTE: "One-hot has no geometry —
embeddings live in meaningful space."
RULE: Similar words live close together. One-hot cannot do this.
-- MISTAKE 2: Training embeddings from scratch --
WRONG:
Train word embeddings from scratch for every new project.
Result: needs billions of words and massive compute.
CORRECT:
Use Word2Vec, GloVe, or sentence-transformers pretrained.
These already learned from the entire internet.
NOTE: "Training from scratch needs billions of words —
pretrained learned that from the internet already."
RULE: Use pretrained embeddings. Do not rebuild from scratch.
Mini Challenge
Mini Challenge
Copy the cosine similarity code from the Examples section and add three new word vectors of your own — pick words from the same category like cricket, football, and tennis. Make up reasonable coordinate vectors where sports words have similar numbers. Calculate cosine similarity between cricket and football, then between cricket and potato. Confirm that sports words score closer to each other than to unrelated words. You just manually verified that similar meaning produces similar numbers.
Quick Quiz
Q1: What is the key difference between one-hot encoding and an embedding? A1: One-hot is sparse and captures no relationships between words. An embedding is dense and encodes meaning in position — similar words get similar coordinates. Q2: What does a cosine similarity score of 0.9987 between two word vectors mean? A2: The two words are very similar in meaning — their vectors point in nearly the same direction in meaning space. Q3: What famous word arithmetic result proves that embeddings capture real meaning relationships? A3: king minus man plus woman produces a vector with 0.9991 cosine similarity to queen — proving meaning is mathematically composable.
Bonus Knowledge
Modern embeddings go far beyond single words. Sentence embeddings map entire sentences into meaning space so you can compare paragraphs, documents, or even questions and answers for similarity. This is the technology behind semantic search — when you type a question into a search engine and it finds relevant pages even if none of them use your exact words. The HuggingFace sentence-transformers library gives you state-of-the-art sentence embeddings in three lines of code. This is also the foundation of how vector databases like Pinecone and Weaviate work — storing millions of embeddings and finding the closest ones in milliseconds, which is exactly how ChatGPT plugins and RAG systems retrieve knowledge.
Key Takeaways
Key Takeaways
- An embedding gives every word a set of coordinates in meaning space — similar words sit close together, unrelated words sit far apart.
- One-hot encoding has no geometry and captures no relationships — embeddings replace it by encoding meaning in position.
- Cosine similarity measures how close two word vectors are — near 1.0 means very similar, near 0.0 means very different.
- Meaning is mathematically composable in embedding space — king minus man plus woman equals queen with 0.9991 similarity.
- Always use pretrained embeddings like Word2Vec, GloVe, or sentence-transformers — never train from scratch.
- Embeddings power search, recommendations, autocomplete, and semantic understanding in every major AI app.
Continue Learning with Rohi
You've used your 3 free Rohi questions. Create a free account to continue learning.