Backpropagation 🏏🔁🧠
Understand how backpropagation works like a cricket coach rewinding match footage to fix every mistake layer by layer, and see exactly how neural networks adjust their weights to get smarter with every epoch.
Day 77: Backpropagation — How AI Learns From Every Mistake
Why Should I Care?
Ever wondered how an AI goes from making terrible predictions to surprisingly accurate ones? The secret is backpropagation. It is the engine behind every neural network that powers YouTube recommendations, Google Photos face recognition, and even the autocorrect on your phone. Without backprop, AI cannot learn a single thing.
Core Concept
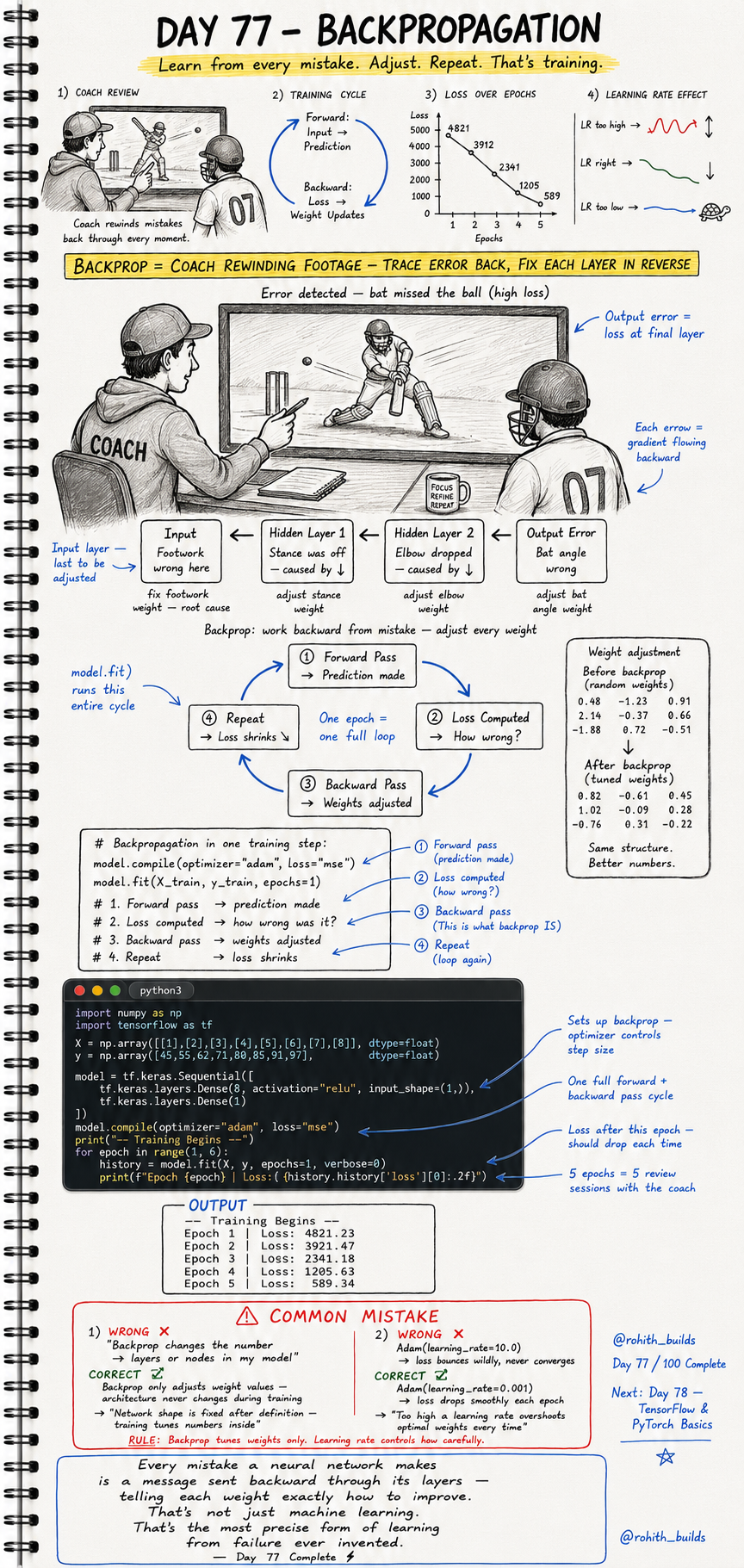
Backpropagation is like a cricket coach rewinding match footage after a bad shot. The bat angle was wrong — that came from the elbow dropping — which came from the stance being off — which started with bad footwork. The coach traces the error all the way back to the root cause and fixes each layer. That is exactly what backprop does inside a neural network. It finds which weight caused the mistake and adjusts it.
How It Works
Every training cycle has four steps that repeat over and over. Step one is the Forward Pass — the model makes a prediction. Step two is Loss Computed — the loss function measures how wrong that prediction was. Step three is the Backward Pass — the error flows backward through every layer and each weight gets adjusted. Step four is Repeat — the loop runs again and the loss keeps shrinking. One full loop of all four steps is called one epoch.
Training Cycle:
1. Forward Pass --> Input goes in, prediction comes out
2. Loss Computed --> How wrong was the prediction?
3. Backward Pass --> Error flows back, weights get adjusted
4. Repeat --> Loss shrinks a little more each time
One Epoch = One full loop of all four steps
Weight adjustment example:
Before backprop (random weights):
0.48 -1.23 0.91
2.14 -0.37 0.66
-1.88 0.72 -0.51
After backprop (tuned weights):
0.82 -0.61 0.45
1.02 -0.09 0.28
-0.76 0.31 -0.22
Same structure. Better numbers. That is all backprop does.
Real World Connection
Think about Instagram reels. The recommendation model predicts which video you will watch next. If you scroll past it immediately, that is a big loss — a wrong prediction. Backprop kicks in, traces the mistake back through the model layers, and adjusts the weights. Next time, the model picks a slightly better video. Do this millions of times across millions of users and suddenly Instagram knows you better than your friends do. That is backprop at scale.
Examples
import numpy as np
import tensorflow as tf
# Simple dataset: X goes from 1 to 8, y is the target
X = np.array([[1],[2],[3],[4],[5],[6],[7],[8]], dtype=float)
y = np.array([45,55,62,71,80,85,91,97], dtype=float)
# Build a small neural network
model = tf.keras.Sequential([
tf.keras.layers.Dense(8, activation="relu", input_shape=(1,)),
tf.keras.layers.Dense(1)
])
# compile sets up backprop — optimizer controls step size
model.compile(optimizer="adam", loss="mse")
print("-- Training Begins --")
# Run 5 epochs = 5 full forward + backward pass cycles
for epoch in range(1, 6):
history = model.fit(X, y, epochs=1, verbose=0)
print(f"Epoch {epoch} | Loss: {history.history[''loss''][0]:.2f}")
# OUTPUT:
# -- Training Begins --
# Epoch 1 | Loss: 4821.23
# Epoch 2 | Loss: 3921.47
# Epoch 3 | Loss: 2341.18
# Epoch 4 | Loss: 1205.63
# Epoch 5 | Loss: 589.34
#
# Loss drops every epoch -- backprop is working
Common Mistakes
Two mistakes beginners make when first learning backpropagation. First, thinking backprop changes the shape of the network. Second, setting the learning rate way too high and watching the model go completely unstable.
-- MISTAKE 1: Thinking backprop changes the network structure --
WRONG:
"Backprop changes the number of layers or nodes in my model."
CORRECT:
Backprop only adjusts weight values inside existing layers.
The network shape is fixed after you define it.
Training just tunes the numbers inside.
NOTE: "Network shape is fixed after definition —
training tunes numbers inside."
RULE: Backprop tunes weights only. Architecture stays the same.
-- MISTAKE 2: Learning rate too high --
WRONG:
model.compile(optimizer=Adam(learning_rate=10.0))
Result: loss bounces wildly, model never converges.
CORRECT:
model.compile(optimizer=Adam(learning_rate=0.001))
Result: loss drops smoothly each epoch.
NOTE: "Too high a learning rate overshoots
optimal weights every time."
Mini Challenge
Mini Challenge
Copy the training code from the Examples section and run it yourself. Then change the number of epochs from 5 to 20 and watch how low the loss goes. Next, try changing the learning rate to 10.0 and see what happens to the loss — does it drop smoothly or go crazy? Screenshot both results. You will see backprop working and breaking right in front of you.
Quick Quiz
Q1: What are the four steps of one training epoch in order? A1: Forward pass, loss computed, backward pass, repeat. Q2: Does backpropagation change the number of layers in a neural network? A2: No. It only adjusts the weight values inside existing layers. The structure never changes during training. Q3: What happens if you set the learning rate too high? A3: The loss bounces around wildly and the model never converges to a good solution.
Bonus Knowledge
The learning rate is one of the most important settings in training. It controls how big each weight adjustment step is after every backward pass. Too high and the model overshoots the best weights every single time like a cricket player swinging way too hard. Too low and the model learns so slowly it would take weeks to train. The Adam optimizer used in the code example is smart — it automatically adjusts the learning rate for each weight individually, which is why it is the most popular optimizer used in production AI systems today.
Key Takeaways
Key Takeaways
- Backpropagation traces the prediction error backward through every layer and adjusts each weight to reduce the mistake.
- Every training epoch has four steps: forward pass, loss computed, backward pass, and repeat.
- Backprop only tunes weight values — it never changes the shape or structure of the network.
- The learning rate controls how big each weight adjustment step is — too high causes chaos, too low causes crawling.
- The Adam optimizer automatically adapts the learning rate per weight, making it the go-to choice for most projects.
- model.fit() in Keras runs the entire forward and backward pass cycle automatically for every epoch.
Continue Learning with Rohi
You've used your 3 free Rohi questions. Create a free account to continue learning.