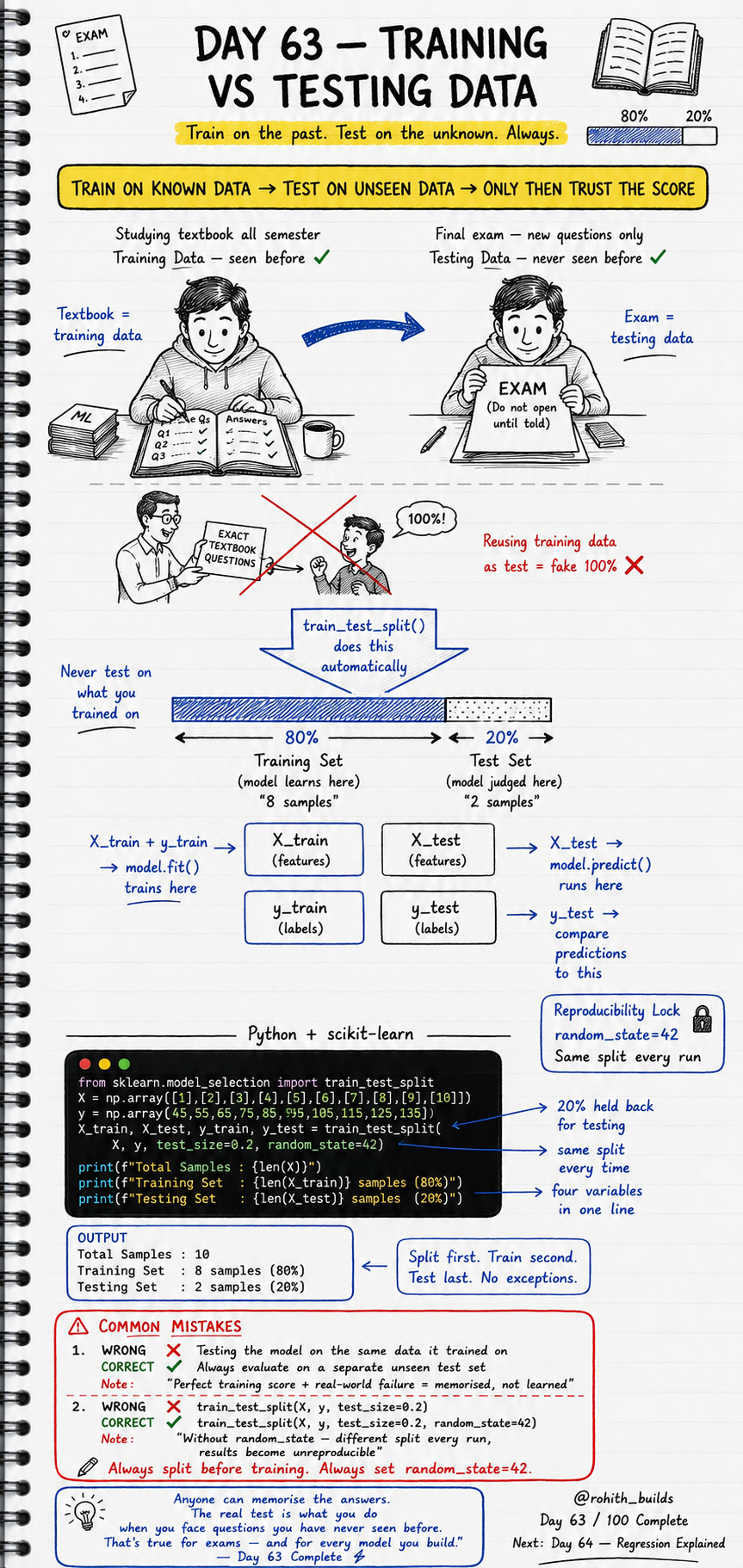
Training vs Testing Data 📚✅🔀
Train on the past. Test on the unknown. Always. A perfect training score means nothing — only the test score tells the truth!
Day 63: Training vs Testing Data — The Real Test Is What You Have Never Seen!
Why Should I Care?
Imagine a student who memorises every answer in the textbook. On exam day their teacher gives the exact same questions — they score 100%. But in real life they face new problems and fail completely. They memorised, they did not learn. Machine learning models can do the same thing. If you test a model on the same data it trained on, it looks perfect — but it has just memorised. The real test is always on data it has never seen before!
Training Set vs Test Set
Training Set — the textbook. The model studies this data and learns the patterns. 80 percent of your data goes here. Test Set — the exam. The model is judged on this data it has never seen. 20 percent of your data goes here. Never touch the test set during training. Never let the model see it until judgment day. Split first, train second, test last. No exceptions!
Splitting Data in Python
from sklearn.model_selection import train_test_split
import numpy as np
X = np.array([[1],[2],[3],[4],[5],[6],[7],[8],[9],[10]])
y = np.array([45,55,65,75,85,95,105,115,125,135])
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
print(f"Total Samples : {len(X)}")
print(f"Training Set : {len(X_train)} samples (80%)")
print(f"Testing Set : {len(X_test)} samples (20%)")
Output: Total 10, Training 8 samples, Testing 2 samples. test_size=0.2 holds back 20 percent for testing. random_state=42 locks the shuffle — same split every single run, reproducible results. Four variables returned in one line — X_train, X_test for features and y_train, y_test for labels!
Training and Evaluating the Full Pipeline
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
import numpy as np
X = np.array([[1],[2],[3],[4],[5],[6],[7],[8],[9],[10]])
y = np.array([45,55,65,75,85,95,105,115,125,135])
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
model = LinearRegression()
model.fit(X_train, y_train)
predictions = model.predict(X_test)
print(f"Predictions : {predictions}")
print(f"Actual : {y_test}")
model.fit(X_train, y_train) — model learns only from training data. model.predict(X_test) — model predicts on test data it has never seen. Compare predictions to y_test to see how well it actually learned versus just memorised. This is the correct and only honest evaluation!
Real World Connection
When Google trains its spam filter it uses millions of old emails as training data. Then it tests on new emails coming in today — data the model never saw during training. When a self-driving car model is trained, it learns on thousands of recorded drives. It is tested on brand new routes it has never seen. When a hospital trains a disease prediction model, it trains on old patient records and tests on new patients. Training on known data, testing on unknown data — always this way in every real ML system!
Common Mistakes
Mistake 1 — Testing on training data.
model.fit(X, y)
model.score(X, y) # WRONG — testing on same data it trained on, fake score!
model.fit(X_train, y_train)
model.score(X_test, y_test) # CORRECT — tested on unseen data, real score!
Mistake 2 — Missing random_state.
train_test_split(X, y, test_size=0.2) # WRONG — different split every run!
train_test_split(X, y, test_size=0.2, random_state=42) # CORRECT — same split every run!
Mini Challenge
Mini Challenge
Create a dataset of 20 houses with size and price. Use train_test_split to split it 80/20 with random_state=42. Train a LinearRegression model on training data only. Predict prices on the test set. Print the predicted prices alongside the actual prices side by side. Check how close they are. You just ran the same honest model evaluation pipeline that every ML engineer at Google, Amazon and Zomato uses before shipping any model to production!
Quick Quiz
Q: Why should you never test a model on the same data it trained on? A: The model memorises the answers — you get a fake perfect score that fails on real new data!
Q: What does random_state=42 do in train_test_split? A: Locks the random shuffle — same split every run so results are reproducible!
Q: What is the correct order of the ML pipeline? A: Split first, train second, test last — no exceptions!
Key Takeaways
Key Takeaways
- Always split data before training — 80% training, 20% testing.
- Never test a model on data it trained on — that is memorisation not learning.
- train_test_split() splits data into X_train, X_test, y_train, y_test in one line.
- Always set random_state=42 for reproducible results every run.
- The real test is always on data the model has never seen before!
Continue Learning with Rohi
You've used your 3 free Rohi questions. Create a free account to continue learning.