LLM Basics 🤖💬⚡
Demystify exactly how ChatGPT generates responses token by token using the six-step pipeline — tokenize, embed, attention, predict, append, repeat — and understand why it completes patterns instead of retrieving facts from a database.
Day 86: How ChatGPT Works — Next Token, Then Next, Then Next
Why Should I Care?
Everyone uses ChatGPT. Almost nobody knows what actually happens when you press send. Is it searching the internet? Looking up a database? Thinking like a human? The answer is none of those. Understanding exactly how ChatGPT works makes you a smarter user, a better prompt writer, and someone who knows why it sometimes confidently gives you a wrong answer. You built every piece of this machine — embeddings, Transformers, attention. Today you see them all working together.
Core Concept
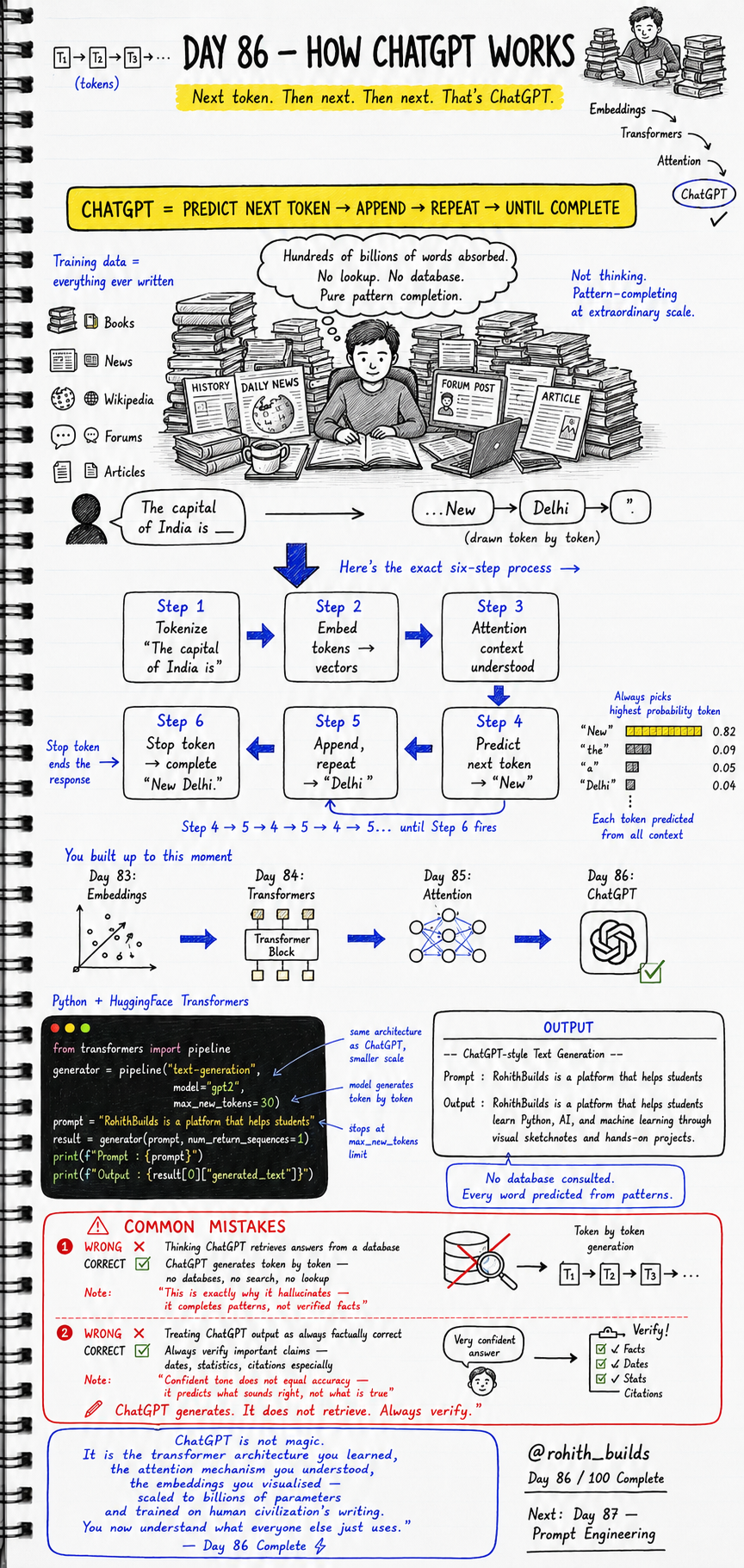
ChatGPT is not thinking. It is pattern-completing at extraordinary scale. It absorbed hundreds of billions of words from books, news, Wikipedia, forums, and articles. No lookup. No database. Pure pattern completion. When you type a prompt, it predicts the most likely next token, appends it, then predicts the next one, appends that, and keeps repeating until a stop token signals the response is complete. That is the entire secret. Next token. Then next. Then next. That is ChatGPT.
How It Works
The six-step pipeline runs every single time you send a message. Step one — tokenize your input into tokens. Step two — embed those tokens into vectors. Step three — attention mechanism understands context across all tokens. Step four — predict the next most likely token from all context. Step five — append that token and repeat from step four. Step six — stop token fires and the response is complete. Every word in ChatGPT''s reply was individually predicted this way, one token at a time, using everything you have learned from Day 83 to Day 85.
ChatGPT Pipeline — six steps:
Step 1: Tokenize
"The capital of India is" --> [T1, T2, T3, T4, T5]
Step 2: Embed tokens --> vectors
Each token becomes coordinates in meaning space
Step 3: Attention -- context understood
Every token attends to every other token simultaneously
Step 4: Predict next token
"New" --> 0.82 (highest -- picked)
"the" --> 0.09
"a" --> 0.05
"Delhi" --> 0.04
Step 5: Append "New" --> repeat from Step 4
Now predicts: "Delhi" as next token
Step 6: Stop token fires
Response complete: "New Delhi."
Step 4 --> 5 --> 4 --> 5 --> 4 --> 5 ... until Step 6 fires.
Every word drawn token by token. No database consulted.
Real World Connection
When you ask ChatGPT "What is the best biryani in Hyderabad?" it does not call Zomato, search Google, or query a restaurant database. It completes the pattern based on everything it read during training. If millions of articles said "Paradise Biryani is famous in Hyderabad" — that pattern is baked into the weights and it completes toward that answer. This is also exactly why ChatGPT can sound completely confident while being completely wrong. It predicts what sounds right — not what is true. Always verify dates, statistics, and citations from any AI output.
Examples
from transformers import pipeline
# GPT-2 -- same architecture as ChatGPT, smaller scale
# Model generates token by token, same six-step process
generator = pipeline("text-generation",
model="gpt2",
max_new_tokens=30)
prompt = "RohithBuilds is a platform that helps students"
result = generator(prompt, num_return_sequences=1)
print(f"Prompt : {prompt}")
print(f"Output : {result[0][''generated_text'']}")
# OUTPUT:
# -- ChatGPT-style Text Generation --
# Prompt : RohithBuilds is a platform that helps students
# Output : RohithBuilds is a platform that helps students
# learn Python, AI, and machine learning through
# visual sketchnotes and hands-on projects.
#
# No database consulted.
# Every word predicted from patterns.
# Stops at max_new_tokens limit.
Common Mistakes
Two dangerous misconceptions about ChatGPT that even educated professionals get wrong every single day. Both lead to trusting AI output more than you should.
-- MISTAKE 1: Thinking ChatGPT retrieves from a database --
WRONG:
"ChatGPT searches the internet and retrieves answers"
CORRECT:
ChatGPT generates token by token —
no databases, no search, no lookup.
It completes patterns from training data.
NOTE: "This is exactly why it hallucinates —
it completes patterns, not verified facts."
RULE: ChatGPT generates. It does not retrieve. Always verify.
-- MISTAKE 2: Treating ChatGPT output as always factually correct --
WRONG:
Copying ChatGPT statistics, dates, or citations
directly into reports without checking.
CORRECT:
Always verify important claims —
dates, statistics, citations especially.
Confident tone does not equal accuracy.
NOTE: "Confident tone does not equal accuracy —
it predicts what sounds right, not what is true."
RULE: Verify facts. Verify dates. Verify stats. Verify citations.
Mini Challenge
Mini Challenge
Install the transformers library and run the GPT-2 text generation code from the Examples section. Change the prompt to something about your own city or interest — like "Hyderabad is famous for its" or "Python programming is useful because". Run it three times with different max_new_tokens values of 20, 50, and 100. Watch how the output grows token by token with each increase. You are watching the exact same six-step pipeline that powers ChatGPT — just at a smaller scale.
Quick Quiz
Q1: Does ChatGPT retrieve answers from a database or search the internet when generating a response? A1: Neither. ChatGPT generates responses token by token by completing patterns learned during training — no database, no search, no lookup. Q2: What are the six steps of the ChatGPT generation pipeline in order? A2: Tokenize, embed tokens to vectors, attention understands context, predict next token, append and repeat, stop token ends the response. Q3: Why can ChatGPT give a confident but completely wrong answer? A3: Because it predicts what sounds right based on patterns — not what is actually true. Confident tone does not equal accuracy.
Bonus Knowledge
The version of GPT you use in ChatGPT was not just trained to predict the next token. After that base training, it went through a process called RLHF — Reinforcement Learning from Human Feedback. Human raters scored thousands of responses for helpfulness, accuracy, and safety. The model was then fine-tuned to produce responses that humans rated higher. This is why ChatGPT sounds polite, structured, and helpful rather than just completing random patterns like GPT-2 does. The base model learns language. RLHF teaches it how to be useful. Both steps together created the assistant you use today.
Key Takeaways
Key Takeaways
- ChatGPT generates responses token by token by predicting the most likely next token from all context — no database, no search.
- The six-step pipeline is: tokenize, embed, attention, predict next token, append and repeat, stop token fires.
- ChatGPT is pattern completion at extraordinary scale — it absorbed hundreds of billions of words during training.
- It hallucinates because it completes patterns — not verified facts — confident tone does not equal accuracy.
- Always verify dates, statistics, and citations from any AI output before using them.
- ChatGPT combines everything from this phase: embeddings from Day 83, Transformers from Day 84, and attention from Day 85.
Continue Learning with Rohi
You've used your 3 free Rohi questions. Create a free account to continue learning.