Forward Pass ➡️🧠⚡
Learn exactly what happens inside a neural network when it makes a prediction — data flows one direction through four steps: multiply, add bias, activate, and pass forward — and why weights never change going forward.
Day 74: Forward Propagation
Why Should I Care?
Every time Google Translate converts your sentence, every time a doctor''s AI reads an X-ray, every time Instagram tags your face in a photo — one thing happens first. A forward pass. Data flows through the network layer by layer until a prediction comes out. Before a network can learn anything, it must first be able to predict something. Forward propagation is that prediction step. And today you will see exactly what happens inside — step by step.
Core Concept
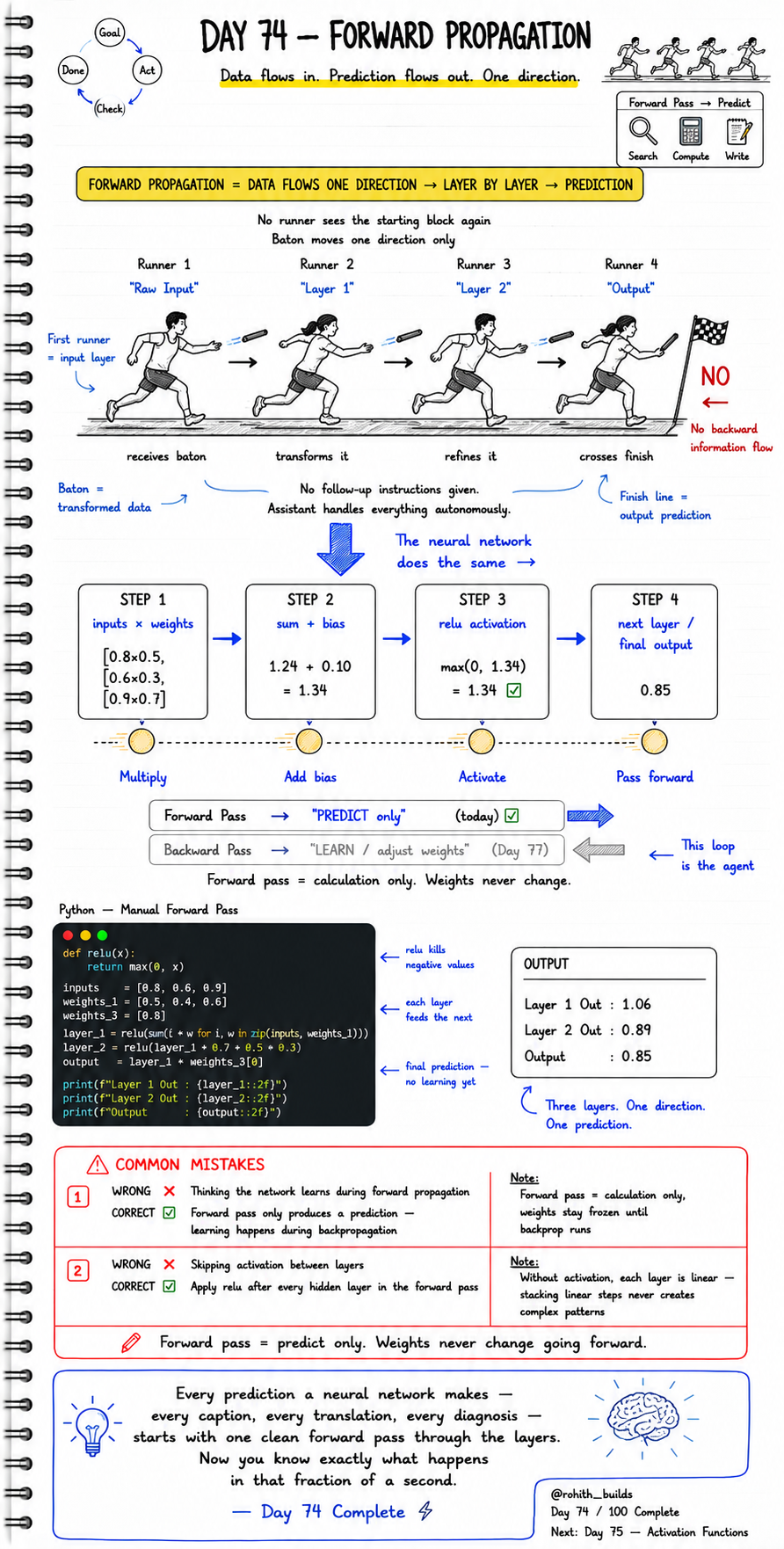
Forward propagation means data flows in one direction only — from the input layer through every hidden layer to the output layer — and a prediction comes out at the end. No backward flow. No skipping layers. No learning during this step. Weights stay frozen. The forward pass is calculation only. The network is predicting, not yet learning. Learning happens later during backpropagation. Today is only about the forward direction.
How It Works
Think of a relay race. Runner 1 starts with the raw baton — that is your input data. Runner 1 passes it to Runner 2 who transforms it. Runner 2 passes to Runner 3 who refines it. Runner 4 crosses the finish line with the final answer — that is your prediction. No runner goes backward. No runner sees the starting block again. Baton moves one direction only. Inside a neural network, each layer does four things with the data it receives: multiply, add bias, activate, pass forward.
STEP 1: inputs x weights --> [0.8x0.5, 0.6x0.3, 0.9x0.7]
STEP 2: sum + bias --> 1.24 + 0.10 = 1.34
STEP 3: relu activation --> max(0, 1.34) = 1.34
STEP 4: pass to next layer --> 0.85 (final output)
Multiply --> Add Bias --> Activate --> Pass Forward
Real World Connection
When you type a message in WhatsApp and it auto-suggests the next word — a forward pass just ran in milliseconds. Your typed words are the inputs. Hidden layers find grammar patterns, word context, your chat history patterns. The output layer predicts the most likely next word and shows it above your keyboard. The whole thing — inputs in, suggestion out — is one clean forward pass through the layers. No learning happening. Just predicting. Weights frozen. Data flowing one way.
Examples
def relu(x):
return max(0, x)
inputs = [0.8, 0.6, 0.9]
weights_1 = [0.5, 0.4, 0.6]
weights_3 = [0.8]
layer_1 = relu(sum(i * w for i, w in zip(inputs, weights_1)))
layer_2 = relu(layer_1 + 0.7 + 0.5 + 0.3)
output = layer_2 * weights_3[0]
print(f"Layer 1 Out : {layer_1:.2f}")
print(f"Layer 2 Out : {layer_2:.2f}")
print(f"Output : {output:.2f}")
# OUTPUT:
# Layer 1 Out : 1.06
# Layer 2 Out : 0.89
# Output : 0.85
# Three layers. One direction. One prediction.
# Weights never changed. This is predict only.
Common Mistakes
Mistake 1 — Thinking the network learns during the forward pass:
-- WRONG:
Forward pass runs --> weights update automatically.
-- CORRECT:
Forward pass = calculation only.
Weights stay completely frozen until backpropagation runs.
Learning happens in the backward pass -- not here.
Forward pass only produces a prediction.
Mistake 2 — Skipping activation between layers:
-- WRONG:
layer_1 = sum(i * w for i, w in zip(inputs, weights_1))
layer_2 = layer_1 + some_bias
# no relu applied -- layers are just linear math stacked
-- CORRECT:
layer_1 = relu(sum(i * w for i, w in zip(inputs, weights_1)))
layer_2 = relu(layer_1 + some_bias)
# relu after every hidden layer -- gives each step real power
# without activation, stacking linear steps never creates
# complex patterns -- depth means nothing
Mini Challenge
Mini Challenge
Open Google Colab. Copy the manual forward pass code from the Examples section. Change inputs to [0.2, 0.9, 0.4] and run. What does Layer 1, Layer 2, and Output print? Now set all inputs to [0.0, 0.0, 0.0] and run again. What happens to every layer output? That zero result is exactly why bias matters — it keeps neurons alive even when inputs are empty. You just ran a full forward pass by hand. That is exactly what TensorFlow does internally at every predict call.
Quick Quiz
Q: What are the four steps of forward propagation inside one layer?
A: Multiply inputs by weights, add bias, apply activation function like relu, then pass the result forward to the next layer.
Q: Do weights change during the forward pass?
A: No. Weights stay completely frozen during forward propagation. The forward pass is prediction only. Weights only change during backpropagation.
Q: What does relu do during the forward pass?
A: ReLU kills any negative values by replacing them with zero and passes positive values through unchanged — this stops layers from collapsing into one flat linear calculation.
Bonus Knowledge
Forward propagation and backward propagation together form the full learning loop of a neural network. Forward pass: data in, prediction out, weights frozen. Backward pass: compare prediction to real answer, calculate error, adjust weights to reduce that error. This loop runs thousands of times during training. Each loop the network gets a little better. Today you learned the first half — the forward pass. Day 77 will cover the backward pass and how weights actually learn. Every prediction a neural network ever makes — every caption, every translation, every diagnosis — starts with one clean forward pass through the layers.
Key Takeaways
Key Takeaways
- Forward propagation means data flows one direction only — input to hidden layers to output — no going back.
- Each layer does four things: multiply inputs by weights, add bias, apply activation, pass forward.
- The forward pass is prediction only — weights never change during this step.
- ReLU activation must be applied after every hidden layer — without it, depth means nothing.
- Learning happens during backpropagation, not during the forward pass.
- Every smart prediction any AI makes — translation, diagnosis, recommendation — starts with one clean forward pass.
- Forward pass = predict only. Weights never change going forward. Remember that line.
Continue Learning with Rohi
You've used your 3 free Rohi questions. Create a free account to continue learning.