Classification 🗂️🤖✅
Learn how machine learning classification predicts which category an input belongs to. Build your first classifier using scikit-learn and LogisticRegression.
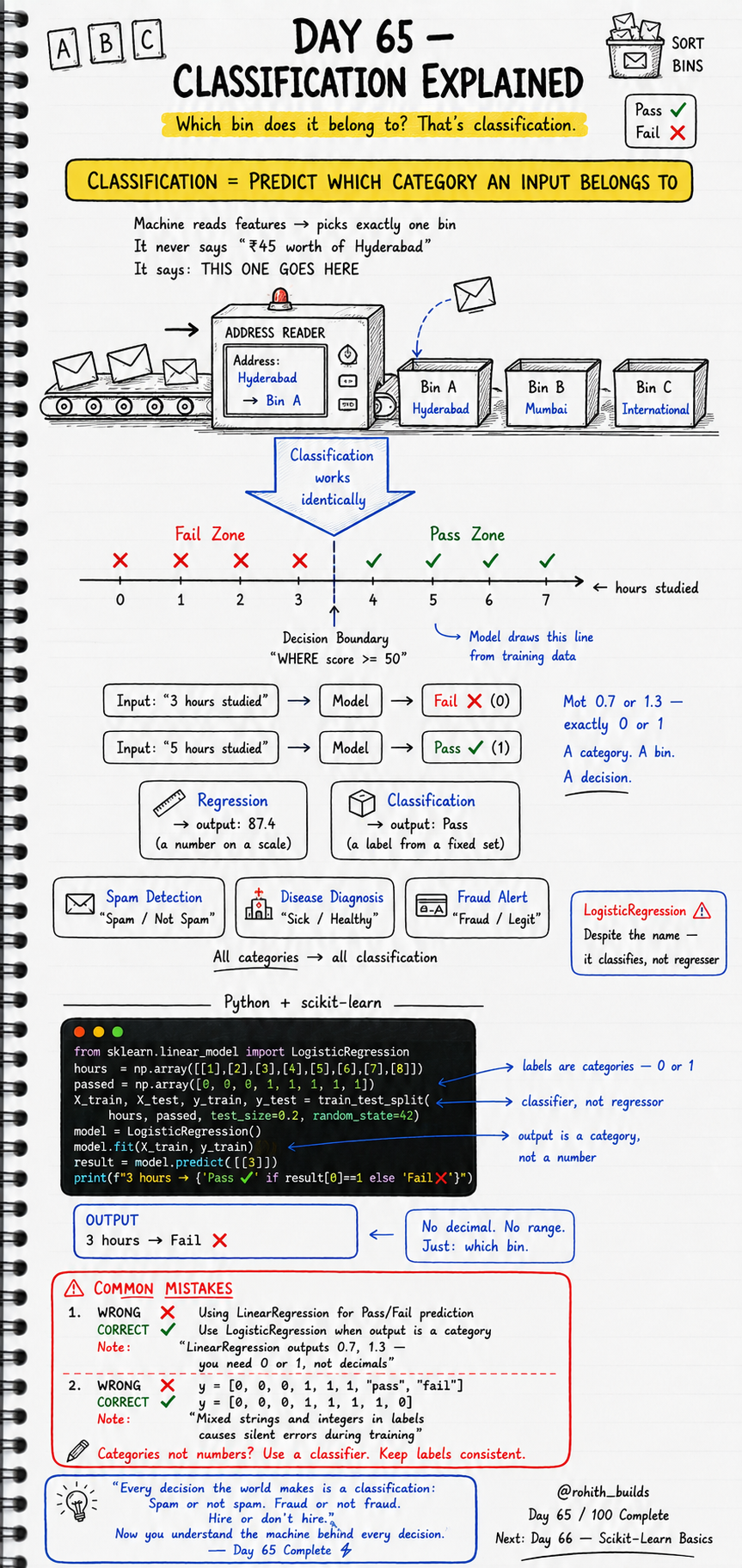
Day 65: Classification Explained
Why Should I Care?
Every time Gmail moves a message to your spam folder, that is classification. Every time PhonePe flags a suspicious transaction as fraud, that is classification. Every time a hospital test says sick or healthy, that is classification. The machine does not guess a number — it picks a bin. Pass or Fail. Spam or Not Spam. Fraud or Legit. Once you understand this, you understand the engine behind almost every smart decision an app makes.
Core Concept
Classification means predicting which category an input belongs to. The model reads features, draws a decision boundary, and assigns a label. It never says "87.4" — it says "Pass" or "Fail". Exactly 0 or 1. A category. A bin. A decision. Think of it like a post office address reader — it does not measure how far the letter needs to travel. It just reads the address and drops it into Bin A, Bin B, or Bin C. That is classification working identically.
How It Works
The model learns from training data where the answer is already known. It finds a decision boundary — a line that separates the categories. For example, students who studied 4 or more hours pass. Below 4 hours, they fail. The model draws that line automatically from the data. When you give it a new input — say 3 hours studied — it checks which side of the line it falls on and gives you a label, not a number. In Python, we use LogisticRegression from scikit-learn. Despite the name, it is a classifier — not a regressor.
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import numpy as np
# Hours studied (features) and Pass/Fail labels (0 = Fail, 1 = Pass)
hours = np.array([[1],[2],[3],[4],[5],[6],[7],[8]])
passed = np.array([0, 0, 0, 1, 1, 1, 1, 1])
# Split into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(
hours, passed, test_size=0.2, random_state=42
)
# Train the classifier
model = LogisticRegression()
model.fit(X_train, y_train)
# Predict for 3 hours studied
result = model.predict([[3]])
print(f"3 hours -> {'Pass' if result[0]==1 else 'Fail'}")Real World Connection
Think about Google Pay detecting a fraud transaction. It reads features — amount, location, time, device — and asks: which bin does this belong to? Fraud or Legit. It does not output "this transaction is 73.6% suspicious". It outputs: Fraud. Block it. PUBG uses the same idea to detect cheaters — it reads your gameplay data and classifies you as a fair player or a hacker. Instagram classifies every comment as safe or hate speech before it ever appears on your screen. Every smart decision in every app you use runs on classification.
Examples
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import numpy as np
hours = np.array([[1],[2],[3],[4],[5],[6],[7],[8]])
passed = np.array([0, 0, 0, 1, 1, 1, 1, 1])
X_train, X_test, y_train, y_test = train_test_split(
hours, passed, test_size=0.2, random_state=42
)
model = LogisticRegression()
model.fit(X_train, y_train)
# Test multiple predictions
for h in [2, 4, 6]:
result = model.predict([[h]])
label = "Pass" if result[0] == 1 else "Fail"
print(f"{h} hours studied -> {label}")
# Output:
# 2 hours studied -> Fail
# 4 hours studied -> Pass
# 6 hours studied -> PassCommon Mistakes
Two mistakes almost every beginner makes with classification. First — using LinearRegression when the output is a category. Linear models output decimals like 0.7 or 1.3 — you need exactly 0 or 1. Second — mixing strings and integers in your labels. That causes silent errors during training and your model learns nothing useful.
# WRONG - Using LinearRegression for Pass/Fail prediction
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, y_train)
# Outputs 0.7 or 1.3 — decimals, not categories
# LinearRegression is for numbers, not bins
# CORRECT - Use LogisticRegression when output is a category
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
# Outputs exactly 0 or 1 — a clean category every time
# ------------------------------------------
# WRONG - Mixed strings and integers in labels
y = [0, 0, 0, 1, 1, 1, "pass", "fail"]
# Mixed types cause silent errors during training
# Your model trains on garbage and gives garbage back
# CORRECT - Keep labels consistent, integers only
y = [0, 0, 0, 1, 1, 1, 1, 0]
# All integers — clean, consistent, correct
# Categories not numbers? Use a classifier. Keep labels consistent.Mini Challenge
Mini Challenge
You are building a loan approval model for a small bank. Create a dataset with 8 applicants — each with a monthly income value. Label incomes below 20000 as 0 (rejected) and 20000 or above as 1 (approved). Train a LogisticRegression model and predict whether an applicant with income 15000 gets approved or rejected. Print the result as "Approved" or "Rejected" — no decimals, no ranges, just the decision.
Quick Quiz
Q: What is the key difference between regression and classification?
A: Regression outputs a number on a scale like 87.4. Classification outputs a label from a fixed set like Pass or Fail — exactly 0 or 1.
Q: Why do we use LogisticRegression for classification even though the name says regression?
A: Despite the name, LogisticRegression is a classifier — it outputs categories, not decimals. It is one of the most common beginner mistakes to confuse it with LinearRegression.
Q: What happens if you mix strings and integers in your labels like [0, 1, "pass", "fail"]?
A: It causes silent errors during training. The model gets confused and learns nothing useful. Always keep labels consistent — integers only.
Bonus Knowledge
Classification is not always just two categories. That is called binary classification — Pass or Fail, Spam or Not Spam. But you can also classify into three or more categories — this is called multi-class classification. For example, sorting emails into Inbox, Promotions, Social, and Spam is a 4-class classification problem. Scikit-learn handles both with the same code. Also — the decision boundary does not have to be a straight line. More advanced models like Decision Trees and Random Forests draw curved, complex boundaries that catch patterns a straight line would miss. Today you learned the foundation. Everything else builds on top of this.
Key Takeaways
Key Takeaways
- Classification predicts which category an input belongs to — a bin, a label, a decision.
- The output is always a fixed label like 0 or 1, Pass or Fail — never a decimal on a scale.
- The model learns a decision boundary from training data and uses it to classify new inputs.
- Use LogisticRegression from scikit-learn for classification — despite the name, it is a classifier not a regressor.
- Never use LinearRegression for categories — it outputs decimals like 0.7, not clean labels.
- Always keep your labels consistent — integers only. Mixed types cause silent training errors.
- Real apps use classification everywhere — spam detection, fraud alerts, disease diagnosis, cheat detection.
- Binary classification is two categories. Multi-class is three or more. Scikit-learn handles both the same way.
Continue Learning with Rohi
You've used your 3 free Rohi questions. Create a free account to continue learning.